
You are currently browsing the daily archive for April 11, 2009.
Werner Vogels (Amazon.com’s CTO) has an interesting article on his blog about the necessary trade-offs involved in building large reliable distributed databases. It seems that some of these ideas could be useful when thinking about building large sensing networks, for example groups of mobile robots (e.g. UAVs) collecting data on their environments (this is the main focus of the projects SWARMS and HUNT here at Penn). As mobile robotic networks grow in size, some robots will probably have to make decisions without having time to collect all the currently available useful information from all other robots. Moreover, just as with web services, a robotic network is expected to be highly available. Currently if communication is lost with an UAV for only a few minutes, the UAV is programmed to return to its base automatically. Hence temporary communication loss can mean the end of a critical mission. With a network of robots, we can think of implementing some degree of fault-tolerance, so that the service can still perform as expected even if some node or particular communication link fails. It might be useful in these scenarios to think about the fundamental limits to sharing consistent information between decision/sensing nodes.
One of the trade-off in distributed databases (DBs) is between high availability and data consistency. Database replication techniques aim at achieving consistency across different nodes, but as a system grows in size, availability becomes an issue. In 2000, Eric Brewer conjectured that in a shared-data system, only two of the following three properties can be achieved at the same time:
- data consistency,
- system availability,
- and tolerance to network partition1.
Seth Gilbert and Nancy Lynch formalized this conjecture in a 2002 paper2. The system responding to client requests is a distributed shared memory. (Atomic) Consistency requires that the requests act as if they were executing on a single node, one at a time. Availability means that every request received by a non-failing node must result in a response (there is no bound on the response time here). To model partition tolerance, the network is allowed to lose arbitrarily many messages sent from one node to another. The first network model used in that paper is the asynchronous network model3. That is, there is no clock, and nodes must make decisions based only on the messages received and local computations. Under such difficult operating conditions, the impossibility result is clear. For example, consider a network which is available and tolerant to network partitions. Assume now that it is partitioned into 2 components 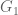
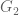
Consider now a partially synchronous model, in which each node in the network has a clock. These clocks all increase at the same rate, but are not synchronized (they may give different values at the same real time). They can be used as local timers to measure the time elapsed since a given event. Also assume that messages not delivered within a known time 

Guaranteeing two of the three properties can be achieved by trivial algorithms. The more interesting problem is to guarantee two of the properties while guaranteeing a weaker version of the third. Web caches are one example of available, partition tolerant, and weakly consistent networks. More generally, for partially synchronous networks, we can design an (centralized) algorithm which is available, partition tolerant, and guarantees a return to consistency within some time limit if no message is lost for a certain time2 (see also the related notion of eventual consistency discussed by Vogels). In large databases used for web services, network partitions are a fact, and therefore complete consistency and system availability cannot be achieved at the same time in general. If a system emphasizes consistency, it may not always be available to take a write. If it emphasizes availability, a read might not always return the most recently completed write. Depending on the application, one might decide to give priority to one property over the other.
Reference
- Brewer, E. A. 2000. Towards robust distributed systems (abstract). In Proceedings of the 19th Annual ACM Symposium on Principles of Distributed Computing (July 16-19, Portland, Oregon): 7
- Gilbert , S., Lynch, N. 2002. Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant Web services. ACM SIGACT News 33(2).
- Lynch, N. 1996. Distributed Algorithms. Morgan Kaufman.
